


When working with large applications, developers often come across different problems. The bigger structure, the harder it is to support it. With time, all the issues might start snowballing, and it will be more difficult to cope with them.
Microservice architecture is not a new topic, but it has gained more and more popularity recently. This development style approaches a huge application as a collection of services. Teams realize that in order to scale, consume resources efficiently and be able to keep the code base of huge software manageable, it’s important to break the monolithic structure into small pieces. In this case, each group focuses on its own domain and develops the solution loosely connected to the rest of the product while keeping its own work cohesive.
The key problem is how to make these pieces talk to each other. In general, there are two ways of doing that — synchronous and asynchronous with the help of various message brokers. For example, RabbitMQ.
In this article, we will cover both communication methods, their pros and cons. We will also dwell on the popular message broker and see how a developer can implement it into a microservice architecture.
Synchronous communication
In this case, we are making direct calls from one service to another, requesting information, or making changes. The response to the request must be received for the execution to continue. This is how you would approach the task in a monolithic app (calling functions one after another in a chain). It is usually considered a quick and ‘dirty’ method with a big benefit in clarity.
Basically, you are replacing local function invocations with remote calls. You know what’s being called and don’t need to walk the extra mile to make APIs (and their clients) support asynchronous communication.
Still, this path is full of obstacles:
If each service is covered with 99.9% SLA (service-level agreement), then with each external call, the SLA keeps dropping. At some point, you find yourself shifting from the maximum of minutes outage per year to hours on certain endpoints;
You have to deal with blocked calls, retries, fallbacks, and caching;
Clients may time out waiting for replies to complex requests;
Almost inevitably, you’ll be forced to deal with distributed transactions. It’s not a direct consequence, but since your architecture is aimed to be synchronous, you will want to make atomic changes in several services. This is a classical distributed monolith which isn’t much better than the original monolith application you were planning to eliminate. In fact, it’s even worse.
Asynchronous communication
This development method is all about using a central bus for notifying all interested parties of events happening inside the app. This is where you eventually come to the majority of books on microservices. The idea of microservice architecture lies in the independence of parts from each other. Think of them as tiny monoliths focused entirely on a single function.
But if all of them are interconnected with direct calls, how are they better than a single application? They aren’t. In fact, having it all in single software would be way better, faster, more resilient to failures, and easier to manage.
In order to support the separation and loose coupling, services should communicate with indirect messages. These are mostly events, but sometimes there is a need to send a command to request an action.
Commands instruct services to take certain actions. A simple example is a scheduled action that emits commands periodically (initiating a weekly report on Sunday at 5 pm). Specific services listen to commands, receive and consume them. If you feel that commands introduce the dependency, you may decide to replace the “CreateWeeklyReport” command with a “WeeklyReportingRequired” event. This way, you make the scheduler not know which service will be preparing the report. It will break the dependency. There are other options, and you need to find what works best for the task at hand.
Events state the changes in the system (user created, comment added, order fulfilled, etc.). Messages of this type are emitted by the services themselves and listened to by others.
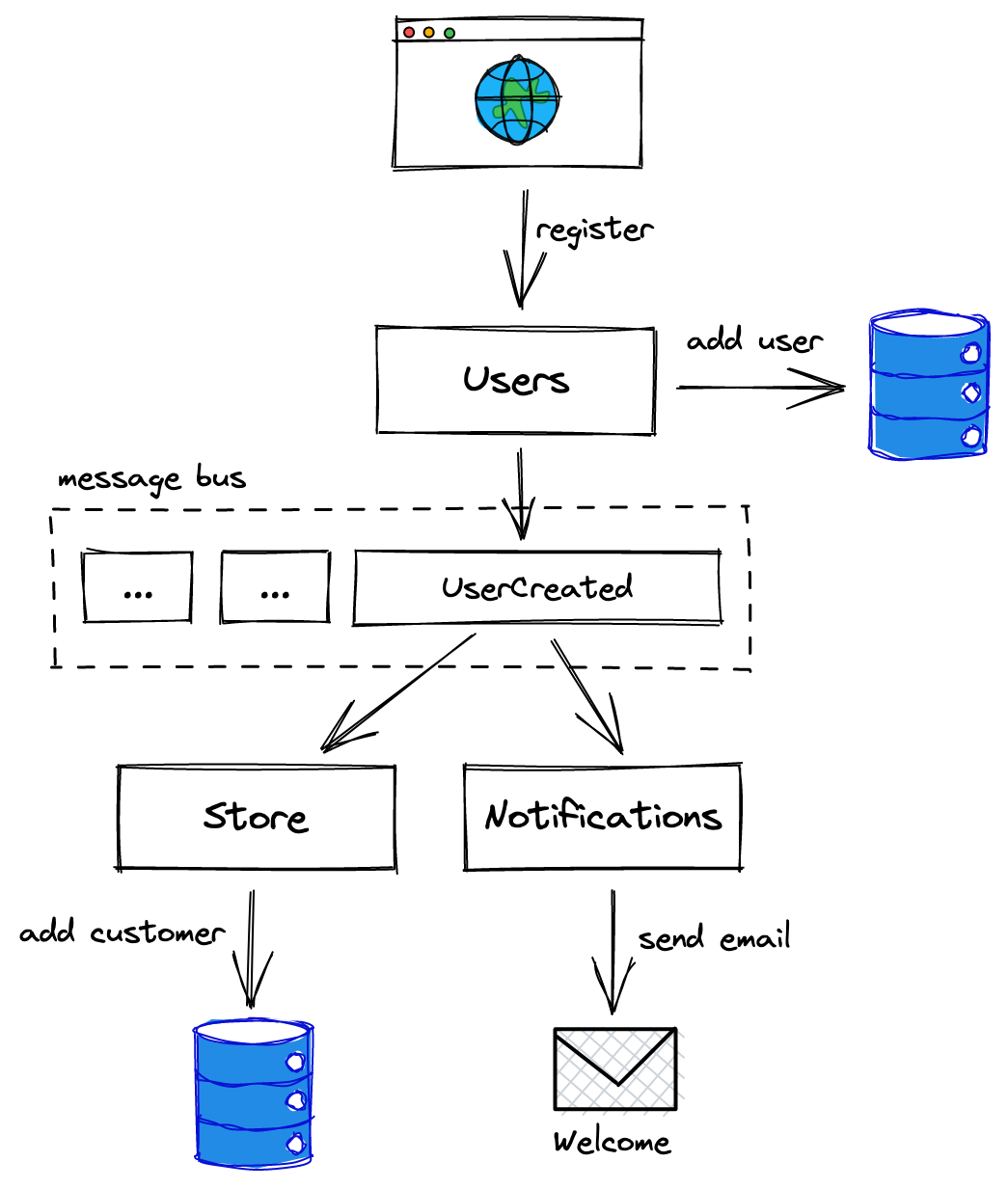
Handling reports looks like a chain reaction. An event is handled and triggers new ones until all related tasks across the services of the application are finished. For example, when you decide to register a new client in your app, you may send an API request to the Users service with a name, email, and other info. Upon successful registration, the service emits a “UserCreated” event which is listened to by the blog (it registers a new author in its database), a notifications service (it sends a welcome email to this new user), and so on. Each of them may emit its own events and trigger more handlers.
RabbitMQ vs. Kafka
Here we come to the important question of how we deliver these events. By this time, it should be obvious that this mechanism is the main artery of the whole application. It should be reliable and fast. A huge structure will be full of processes flying back and forth between numerous services.
There are several battle-tested solutions for this. In order to make a wise decision, a web developer needs to study and consider them carefully. They all have their niches. There are two popular message brokers:
Kafka. If you are reading this, chances are you’ve heard about this one. There are books, courses, and conferences about it. Kafka is a message bus and integrates well with hundreds of tools on the market. It is definitely worth considering. Especially when you want to store events for prolonged periods of time (if not indefinitely).
RabbitMQ is an open-source software, a small and very fast implementation of the Advanced Messaging Queue Protocol (AMQP). Kafka does not support this protocol, by the way. It is a message broker with a concept similar to mailboxes and queues with one or many consumers connected to them. Messages land into exchanges and are directed to specific queues via the routing rules. One important thing that differentiates it from Kafka is that RabbitMQ is consumer-centric, while Kafka is producer-centric. This message bus tracks what consumers have received and processed via the mechanism of acknowledgments (automatic or manual). For you, it means you do not need to store the pointers to the last processed event. The tech handles this for you.
How to use RabbitMQ
Finally, we came to the meat of the article. Here we will see how exactly RabbitMQ can be implemented as a broker in an application.
Imagine that we have a tiny e-commerce app. We break its structure into several services according to their domains:
Users’ service registers future clients so that they can log in and work with the product.
Store service allows managers to fill catalogs with products and take care of inventory while customers browse the wares and place orders. We could break this process down further to separate catalog from inventory, carts, and the ordering system, but let us keep it simple.
Notifications service monitors events and sends emails to users.
You may have noticed that we call people “customers” and “managers” (not “users”) in the Store section. It is who they are in the context of a store. And it is important to see things this way. Yes, you can make it so that an ID of a user in the Users service matches the ID of a customer in the Store section, or you can have a “user_id” field there if you like. What is important is that you follow your business language, but that is a topic for another day.
As described earlier, these processes can be looked at as tiny applications on their own. They have a purpose and can function separately from each other.
The Users service is a list of all clients in the software. They sign up and sign in, change their profiles, reset passwords and do all that people do with their accounts there. We can define and assign roles to them there, too. Alternatively, admins can do that, as well as see the lists of users, edit their profiles, delete them, etc. When the state changes, the Users service emits events (“UserCreated”, “UserUpdated”, “RoleGranted”, etc.). What is emitted and what the fields are is what you decide with the rest of the team.
The Store service allows managers to work with the catalog and inventory while customers list products and place orders. But how managers and customers are added or deleted? This is where the events come into play. We want clients to be added to the Store service database when they appear in the system and listen to an event from the Users, taking notes.
The notifications team also watches for new user events and sends welcome emails to them with the details on how to set their password and what the next steps are.
Now, let’s see how to design all this with RabbitMQ. And we will start with the message format.
Messages
The message bus does not really care about what data it transports. It can be text or binary. You have a huge choice of options, but we suggest sticking to traditional plain text formats (at least at first) for a number of reasons. The main is you will be able to easily read, log, and issue messages manually without any special tools. Of course, sending binary packages will give you faster times, but unless you are building some heavy-load system, this benefit may be outmatched by the difficulties of debugging and tracing.
Here is a typical “UserCreated” message:
{
"id": "d0482898-5a6f-4c90-95d8-aecb35f3bf2d",
"name": "UserCreated",
"time": "2022-11-09T09:36:15Z",
"data": {
"user_id": "e31e52ed-3f84-414a-a03a-55356dcc01aa",
"user_name": "John Smith",
"email": "john@smith.name",
"roles": ["store_manager"]
}
}
It consists of several parts:
“id” is the identity of the message itself. If your service is not naturally idempotent (can safely handle the same message multiple times) and needs something to identify processed data, this field will come in very handy. RabbitMQ has the “at least once” delivery model, meaning that (in edge cases) the same message can be delivered more than once, and it’s your job to make sure it doesn’t break things;
“name” is the name of an event or a command;
“time” is clearly the time when this message was generated;
“data” is what holds the actual core. The fields set should be well-defined by all interested teams and stored somewhere for reference (even if it’s a text file). It can also be JSON, as in the example. Sometimes JSON Schema is used to describe the format of each message. Then it can be applied to validate incoming transmissions. We’ve also seen other development teams use centralized repository products for storing and navigating the message catalog.
The next step is to figure out how to send transmissions from producers to consumers.
Routing messages
RabbitMQ has rich pathing capabilities. You can read about them in the official documentation. We chose to have a queue per service and direct messages to them from a central exchange via routing keys.
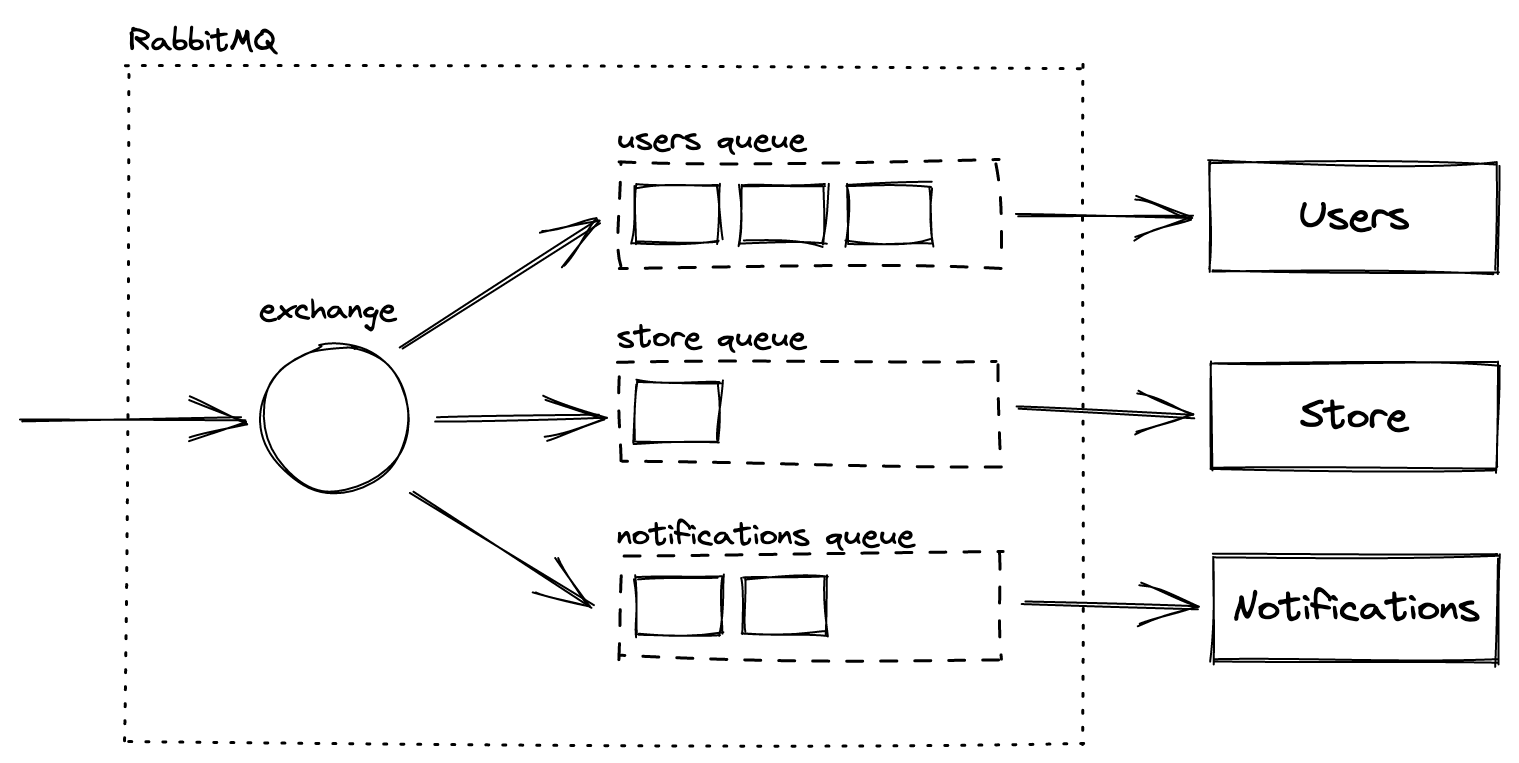
Here is what we need:
An exchange for sending transmissions;
A queue for each service to receive these messages. In the e-commerce case, their names are “store” and“notifications”. Queues are required because RabbitMQ delivers messages to each queue but doesn’t check if all of the consumers receive them. This means that if we’ve connected Store and Notification to the same queue, only one of them will randomly receive data.
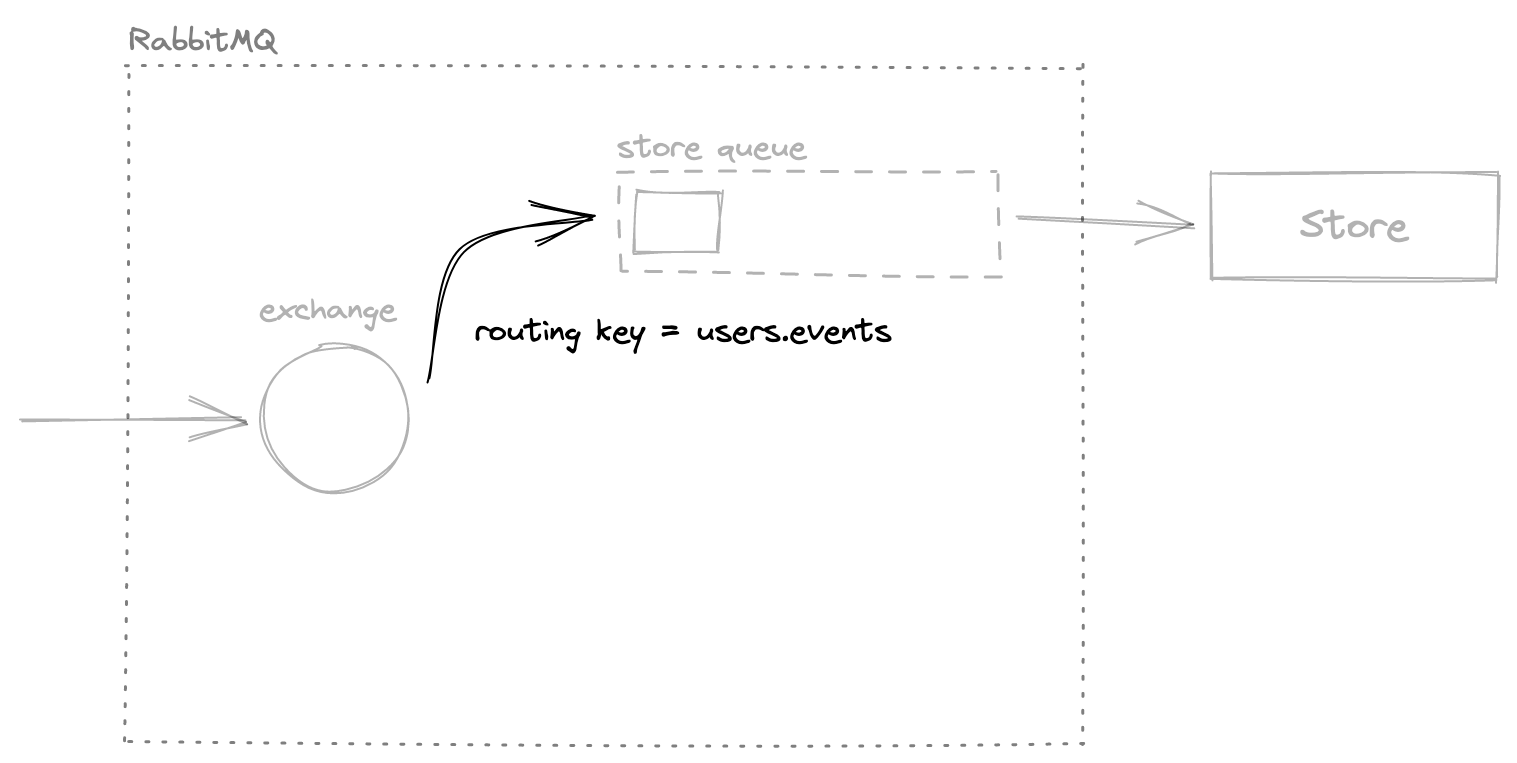
Directing messages from the exchange to queues is easy with routing keys. Let’s assume that when a service sends some event, it passes the info to the exchange with the routing key “<service-name>.events”. Any other service interested in events from this process needs to bind its queue to the exchange with the same key. It’s like a virtual connection between the exchange and queues that tells our message broker to channel transmissions marked with a specific tag to particular queues.
The format of the routing key is arbitrary. Using the key in the above format, we can declare that Store wants to consume events from Users by creating the binding between the exchange and the “store” queue with the key “users.events”. That’s all that it takes.
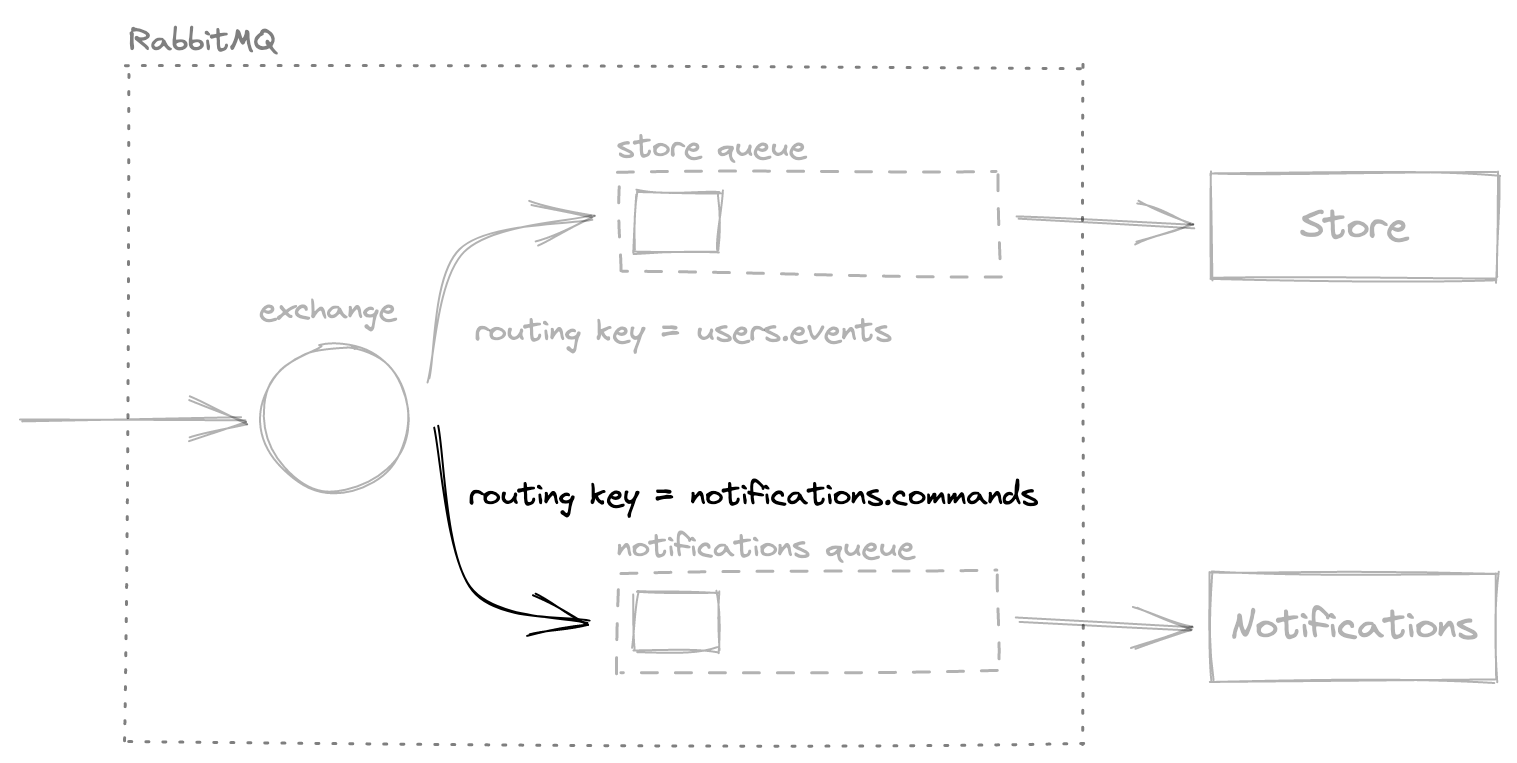
When it comes to sending commands to a service, we use the same principle. This time, a developer creates the binding between the target process and the exchange but works with a slightly different routing key to indicate that commands are expected — “<service-name>.commands”.
For example, notification may need an explicit command for sending a weekly report. In this case, we create a binding between the exchange and the “notifications” queue using the “notifications.commands” key. Now, time to send the command message to the exchange with this route tag. The data will be delivered to the “notifications” queue.
Tips for working with RabbitMQ message bus
Dealing with message brokers is generally easy. However, there are some issues a web developer should be aware of:
RabbitMQ follows the “deliver at least once” principle, which means that the same message may be delivered more than one time. There are two ways to solve this. You can make the handlers idempotent so that they handle the same transmission twice without ruining the whole thing. Alternatively, make sure you record the messages you processed and avoid disaster.
If RabbitMQ (or any other broker, for that matter) crashes, there won’t be any data exchange. Think of a strategy to survive this. We suggest writing events into the database within the same transaction with your data changes and then using a background job to send these events to the message broker. This way, you will be able to retry the delivery until the bus is available.
Avoid using the same RabbitMQ user account to connect your services to the broker. This makes it impossible to:
Track which service is up (or down) and the number of their instances;
Fine-tune permissions to queues;
Monitor usage.
- Do not use the guest account that comes with the fresh installation. It’s important to replace it with custom ones and non-default passwords from day one.
In conclusion
We have covered just the tip of the microservice architecture iceberg. Using RabbitMQ as the message bus in your applications, you can create a stable structure even with huge amounts of elements. Tips will help you design the architecture right, so that messaging will be durable and fault-resistant.